오늘은 블록미디어의 최신뉴스가 올라올때마다 나의 텔레그램으로 뉴스를 내보내는 간단한 프로그램을 만들어 보겠습니다.
필요한 과정은 아래와 같습니다.
1. 파이썬 설치
2. 비주얼스튜디오코드 설치
3. 가상환경 실행
3. request와 BeautifulSoup 라이브러리 설치
4. 텔레그램 봇 만들기
5. 코드 작성
1~4번과정은 추후 다뤄보고, 오늘은 5번만 다뤄보겠습니다.
# 메인 함수: 새로운 글 확인 및 출력
def main():
file_path = 'latest_article.json'
# file_path = '/var/autobot/news/latest_article.json'
latest_article = fetch_latest_article()
saved_article = load_saved_article(file_path)
if latest_article and (saved_article is None or latest_article['title'] != saved_article['title']):
print(f"새로운 글: {latest_article['title']}")
print(f"링크: {latest_article['link']}")
save_article(file_path, latest_article)
telgram.send_telegram_message("도상국의 실시간 코인뉴스: "+latest_article['title']+latest_article['link'])
else:
print("새로운 기사가 없습니다.")메인 함수의 프로세스는 다음과 같습니다.
1. fetch_latest_article 함수로 최신기사의 제목을 크롤링한다.
2.load_saved_article 함수로 기존에 저장된 기사의 제목을 불러온다.
3. if 구문을 사용하여 두 기사의 제목을 비교한다. 제목이 서로 다르다면 새기사가 업데이트 된것이다.
4. 새기사가 업데이트 되었으면 telgrem 모듈을 사용하여 텔레그램에 기사의 제목과 링크를 보낸다.
이번에는 fetch_latest_article함수를 살펴볼게요.
import requests
from bs4 import BeautifulSoup
import json
import os
import telgram
# 함수: 블록미디어 사이트에서 최신 글 1개 크롤링
def fetch_latest_article():
url = "https://www.blockmedia.co.kr/archives/category/press"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 최신 기사 1개 가져오기
article = soup.find('article')
if article:
title = article.find('h2').get_text(strip=True)
link = article.find('a')['href']
return {'title': title, 'link': link}
return None1. 위 함수에서 requests 라이브러리의 역할은 requests.get 을 사용해서 지정된 URL의 본문 내용을 가져옵니다.
2. BeautifulSoup 라이브러리는 가져온 html을 크롤링하기 좋은 형태로 변환해줍니다.
3. 해당 url을 크롬브라우저에서 f12를 누르면 아래와 같은 화면이 나오는데, 여기서 내가 크롤링하고 싶은 컨텐츠의 테그를 찾아야 합니다.

3. soup.find 명령어를 사용해서 'article' 테그에 해당하는 데이터를 찾습니다.
4. 기사의 제목은 h2테그에 있고, 기사의 링크는 a 테그에 있습니다.
5. 기사의 제목은 title에, 기사의 링크는 link변수에 집어넣습니다.
다음은 load_saved_article 함수를 살펴보겠습니다.
# 함수: JSON 파일에서 저장된 최신 기사 불러오기
def load_saved_article(file_path):
if os.path.exists(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
return json.load(file)
return None간단합니다. json.load 명령어로 기존에 json형식으로 저장된 최신기사의 제목을 불러옵니다.
다음은 save_article 함수를 살펴볼게요.
# 함수: 최신 기사를 JSON 파일에 저장하기
def save_article(file_path, article):
with open(file_path, 'w', encoding='utf-8') as file:
json.dump(article, file, ensure_ascii=False, indent=4)역시 간단합니다. json.dump 명령어로 기사제목을 파일경로에 저장합니다.
이렇게 4개의 함수를 살펴봤습니다.
전체 스크립트를 만들어 보면 아래와 같습니다.
import requests
from bs4 import BeautifulSoup
import json
import os
# 함수: 블록미디어 사이트에서 최신 글 1개 크롤링
def fetch_latest_article():
url = "https://www.blockmedia.co.kr/archives/category/press"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
article = soup.find('article')
if article:
title = article.find('h2').get_text(strip=True)
link = article.find('a')['href']
# 본문 내용 크롤링
article_response = requests.get(link)
article_soup = BeautifulSoup(article_response.text, 'html.parser')
content = article_soup.find('div', class_='entry-content').get_text(strip=True)
return {'title': title, 'link': link, 'content': content}
return None
# 함수: JSON 파일에서 저장된 최신 기사 불러오기
def load_saved_article(file_path):
if os.path.exists(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
return json.load(file)
return None
# 함수: 최신 기사를 JSON 파일에 저장하기
def save_article(file_path, article):
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, 'w', encoding='utf-8') as file:
json.dump(article, file, ensure_ascii=False, indent=4)
# 메인 함수: 새로운 글 확인 및 출력
def main():
file_path = 'latest_article.json'
latest_article = fetch_latest_article()
saved_article = load_saved_article(file_path)
if latest_article and (saved_article is None or latest_article['title'] != saved_article['title']):
print(f"새로운 글: {latest_article['title']}")
print(f"링크: {latest_article['link']}")
print(f"본문 내용: {latest_article['content']}")
save_article(file_path, latest_article)
else:
print("새로운 기사가 없습니다.")
# 스크립트 실행
if __name__ == "__main__":
main()
마지막 줄에서 스크립트를 실행할때 if __name__ == "__main__": 를 입력하는 이유는 해당 스크립트가 실행될때만 main함수가 실행되도록 하기 위함인데요. 이구문을 사용하면 이 스크립트를 다른 스크립트에서 임포트해서 사용해도 충돌문제가 발생하지 않습니다.
마지막으로 스크립트의 출력결과 터미널창에서 보여드릴게요.
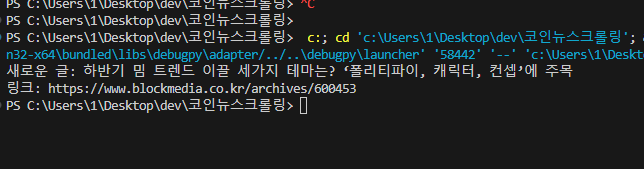
터미널창에서 새로운 기사의 제목과 링크가 잘 출력되는걸 확인했습니다.
이번엔 텔레그램 방에서 어떻게 나오나 보겠습니다.

텔레그램에서도 기사의 제목과 링크가 정상적으로 확인이 됩니다. 이렇게 간단하게 뉴스기사를 크롤링하는 프로그램을 만들어봤습니다.이 방법을 활용하면 본인이 운영하는 커뮤니티에 매일 일정시간마다 자동으로 뉴스기사를 내보낼수 있으니, 그전엔 사람이 해왔던 일을 컴퓨터에게 온전히 맡길수 있습니다.
다음시간엔 텔레그램봇을 만드는 방법과 텔레그램 채널, 그룹, 개인메시지로 보내는 방법에 대해서 다뤄보겠습니다.
카카오톡 일대일 오픈채팅 링크: 개인적으로 일대일 문의가 필요하신분들은 아래 일대일 카카오톡 오픈채팅을 이용해주세요.

